はじめに
Smartsheet フォーラムで、ユーザーが重複する行を除いた値の合計を取得する方法について質問しました。この投稿では、この質問の回答と、この問題を解決するための 2 つの方法について説明します。
質問の要約
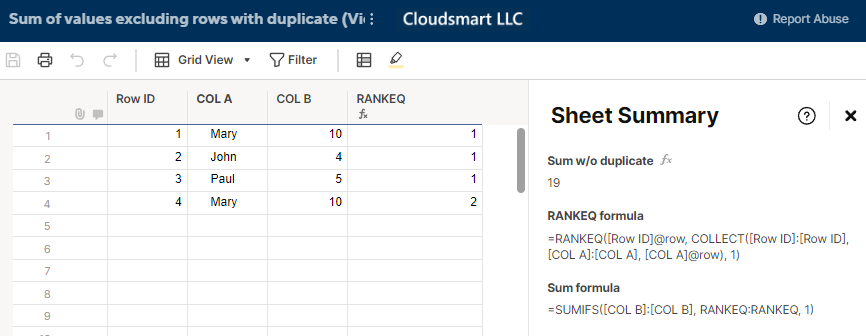
ユーザーは、COL A の対応する条件の最初のインスタンスを除くすべてのインスタンスを除外しながら、COL B の値を合計する必要があると考えていました。重複した値が含まれている可能性があります。(オリジナルのCommunity記事はこちら。)
答えの要約
ベストアンサーは、RANKEQ 関数または MATCH 関数を使用して、重複する行を除く方法を説明しました。
まとめ
RANKEQ 関数は、同じ COL A セル値を持つ行 ID を収集し、ランク付けするために使用されます。次に、このランキングを使用して、行ランキングが 1 である COL B 値を合計します。
MATCH 関数は、行番号列を作成し、現在の行の前の COL A セル値の数をカウントするために使用されます。このカウントを使用して、重複行を除外できます。
どちらの方法も、重複する行を除いた COL B 値の合計を取得するのに役立ちます。
追加情報
- RANKEQ 関数を使用するには、一意の数値範囲が必要です。独自の価値観を持たないと、つながりが生まれてしまいます。セル値が一意である他の列がある場合は、それを使用することもできます。
- 一意のセル値が数値ではなくテキストである場合は、MATCH 関数を使用して行番号列を作成し、現在の行の前の COL A セル値の数をカウントできます。
この投稿がお役に立てば幸いです。
やり取りの翻訳
マリアナ・B・P ✭
COL A の対応する条件の最初のインスタンスを除くすべてのインスタンスを除外しながら、COL B の値を合計する必要があります。重複した値が含まれている可能性があります。
例:
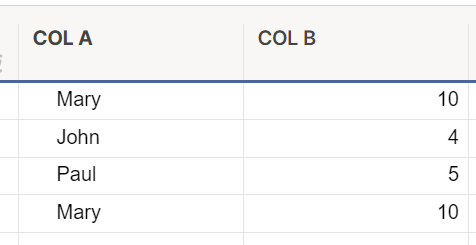
結果は 19 になるはずです。
ベストアンサー
jmyzk_cloudsmart_jp ✭✭✭✭✭✭
こんにちは@マリアナBP
まず、どの行が重複しているかを見つける必要があります。
RANKEQ アプローチ
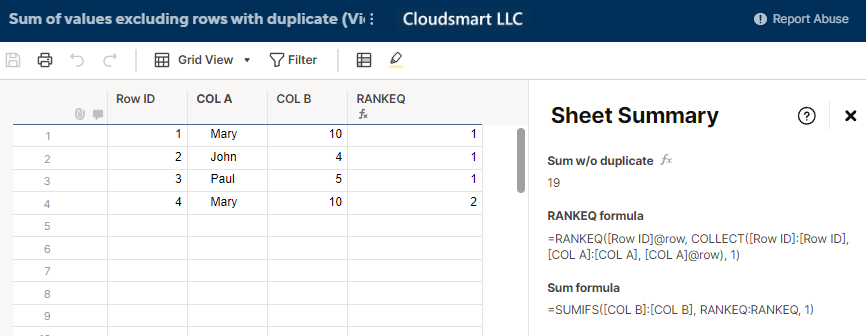
自動番号付けヘルパー列である行 ID を追加し、RANKEQ 関数を使用します。
=RANKEQ([行ID]@row, COLLECT([行ID]:[行ID], [COL A]:[COL A], [COL A]@row), 1)
この関数は、同じ COL A セル値を持つ行 ID を収集し、ランク付けすることを目的としています。次に、このランキングを使用して、行ランキングが 1 である COL B 値を合計する必要があります。
https://app.smartsheet.com/b/publish?EQBCT=a645cb867c7142fa886ec4b2428515e6
マッチアプローチ
この状況で RANKEQ 関数が機能するには、一意の数値範囲が必要です。独自の価値観を持たないと、つながりが生まれてしまいます。セル値が一意である他の列がある場合は、それを使用することもできます。
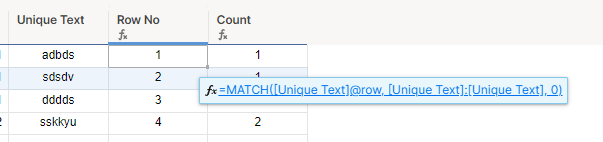
一意のセル値が数値ではなくテキストである場合は、MATCH 関数を使用して行番号列を作成し、現在の行の前の COL A セル値の数をカウントできます。
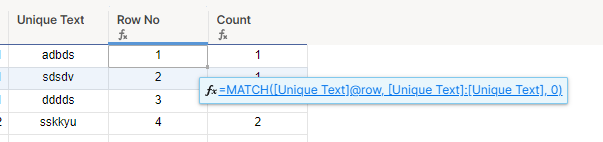
行番号=MATCH([ユニーク テキスト]@row, [ユニーク テキスト]:[ユニーク テキスト], 0)
カウント =COUNTIFS([COL A]:[COL A], [COL A]@row, [行番号]:[行番号], <=[行番号]@row)
答え
マシュー・J・マカティア ✭✭✭✭
こんにちは@マリアナBP
このテーブルに重複したエントリを持たなければならない理由はありますか?おそらく、この問題を解決する方法は、値を合計する前に重複を除外することです。特定の使用例についてさらに詳しく教えていただけますか?
マシュー
マリアナ・B・P ✭
上記で簡単な例を示しましたが、私が作業しているシートには、同じ予算バケットにリンクされている場合があるタスクの数行が含まれています。たとえば、タスク 1、3、5 は同じ予算に割り当てられているため、3 つのタスクの予算値は同じになります。表の最後に、重複を除いた合計予算を合計したいと思います。
jmyzk_cloudsmart_jp ✭✭✭✭✭✭
こんにちは@マリアナBP
まず、どの行が重複しているかを見つける必要があります。
RANKEQ アプローチ
自動番号付けヘルパー列である行 ID を追加し、RANKEQ 関数を使用します。
=RANKEQ([行ID]@row, COLLECT([行ID]:[行ID], [COL A]:[COL A], [COL A]@row), 1)
この関数は、同じ COL A セル値を持つ行 ID を収集し、ランク付けすることを目的としています。次に、このランキングを使用して、行ランキングが 1 である COL B 値を合計する必要があります。
マッチアプローチ
この状況で RANKEQ 関数が機能するには、一意の数値範囲が必要です。独自の価値観を持っていないと、つながりが生まれてしまいます。セル値が一意である他の列がある場合は、それを使用することもできます。
一意のセル値が数値ではなくテキストである場合、MATCH 関数を使用して行番号列を作成し、現在の行の前の COL A セル値の数をカウントできます。
行番号=MATCH([ユニーク テキスト]@row, [ユニーク テキスト]:[ユニーク テキスト], 0)
カウント =COUNTIFS([COL A]:[COL A], [COL A]@row, [行番号]:[行番号], <=[行番号]@row)
{kind=link}
マリアナ・B・P ✭
ありがとう、うまくいきました:)